A previous study used an LLM to run a complete OpenFOAM aerodynamics simulation; a follow-up session then used the same model to validate it experimentally in a smoke tunnel with a 3D-printed bear. The simulation write-up read as a success story. This post tells the other half: the validation was a sequence of confident, plausible, and wrong intermediate outputs — a drag coefficient that was really a different quantity, a freestream "measured" as zero, a model badly mis-sized by vision, a flow-direction "agreement" that was pure noise — each caught only by a human with domain knowledge.
The conclusion is not that LLMs are unfit for experimental work — they are a remarkable force-multiplier. It is that experiments have no safety net: no compiler rejects a wrong unit, no test suite flags a misread column. Human attention at setup, execution, and post-processing is the load-bearing structure. And the reference the analysis is checked against — the CFD itself — can also be wrong; only a careful, human-designed physical measurement is genuine ground truth.
On method: Every error described here is real and taken from the live session. The figures reproduce the actual intermediate and corrected outputs, with the specifics.
Success Stories Hide the Interventions
When an LLM-run project is written up, the narrative flows from prompt to polished result, and the corrections in between vanish — suggesting the model's outputs can be trusted by default. In experimental work that is dangerous, because software has guardrails and experiments do not. A type error fails to compile; a column read from the wrong index just produces a number. A field computed from a misunderstood image produces a field, not a crash. The output looks exactly like a correct result, and the only thing between it and a published conclusion is a human who knows what the answer should roughly be.
"In code, the machine tells you when you are wrong. In an experiment, only physics does — and physics does not raise exceptions. It just quietly lets you publish the mistake."
Six Errors From One Validation
The figure below is the actual correction ledger from the session. Each row: an LLM output that would have been reported, why it was wrong, and the human correction. The pattern: failures are silent. Every wrong value rendered cleanly into a plot or table, none looked anomalous in isolation. Each caught only because external knowledge existed to collide with it.

The Limits of Vision-Based Measurement
The most stubborn failures were visual. Every measurement depends on locating the model to set the pixel-to-meter scale — and the LLM's detection failed repeatedly, by large margins. Smoke occluded the body, the polished floor threw reflections, background clutter competed for the threshold. One pass merged the bear with its own reflection; another returned a wide flat band impossible for the animal. Every downstream "measurement" inherited those errors, silently. The fix wasn't a cleverer prompt; it was a human imposing a known reference scale.
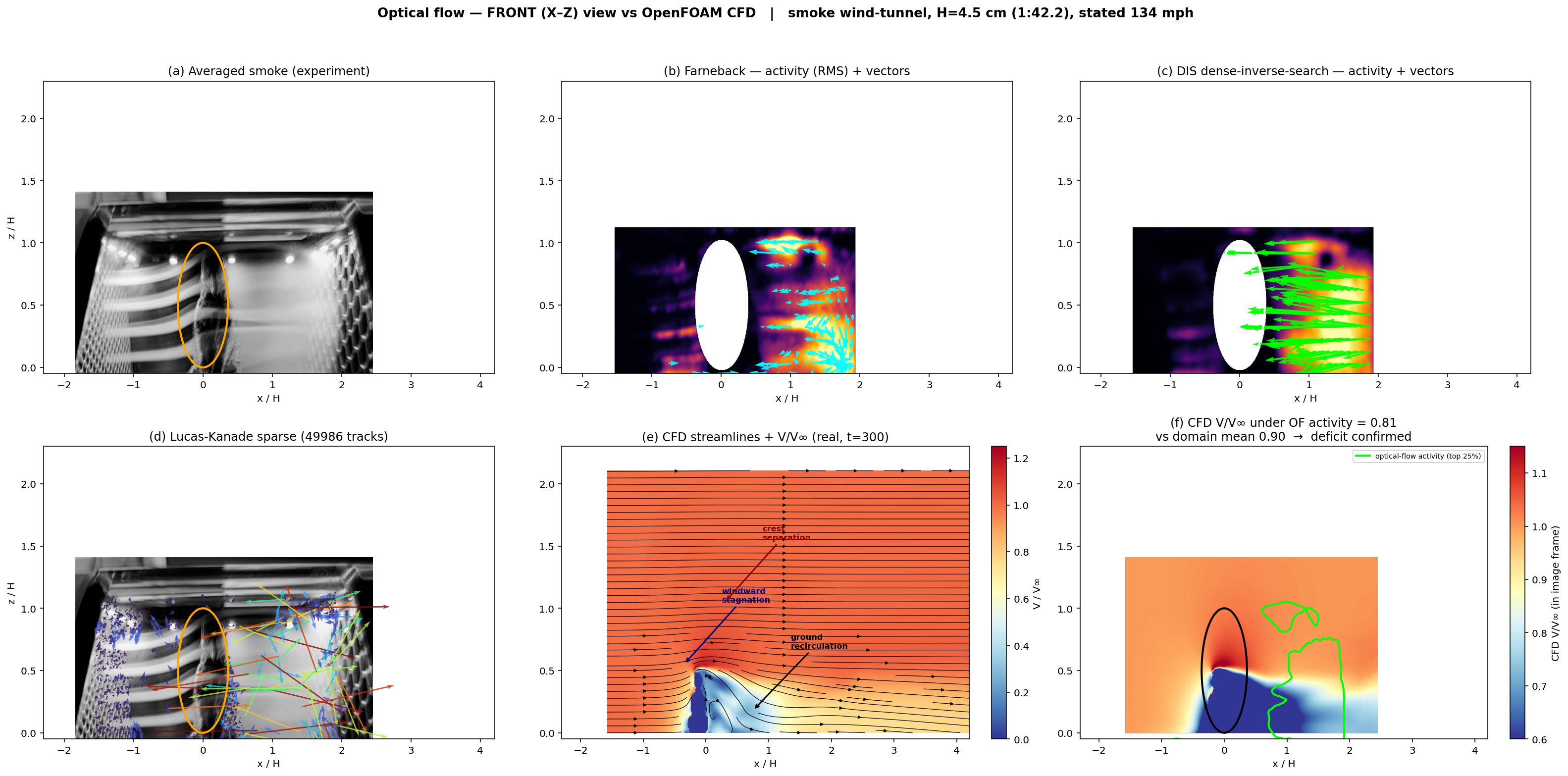
The deeper lesson: an LLM can describe an image fluently, and that fluency invites over-trust. But fluent description is not metric perception. Robustly segmenting an occluded, reflected, low-contrast object and returning an accurate dimension is a capability the model does not reliably have.
Where Vision Breaks for LLMs
Occlusion, reflections, low contrast, and clutter defeat automated detection — exactly the conditions of real flow-visualization imagery. Treat any LLM-derived dimension or calibration from a photograph as a hypothesis to verify against a physical reference, never as a measurement.
Numbers That Look Right and Aren't
The drag coefficient that wasn't. The model read the wrong column of the solver's force output and reported the pitching-moment coefficient as the drag coefficient — the most ordinary off-by-one imaginable, yielding a perfectly reasonable-looking number that was the wrong physical quantity. It was caught only because an earlier study had independently established what the drag should be, giving a reference to collide with.
A freestream of zero. The first velocity extraction reported no upstream flow at all — in a tunnel visibly moving smoke. The cause was genuine physics: steady smoke streaklines are a standing pattern that barely moves frame-to-frame even as fluid races through them, so frame-differencing correctly returns nothing. Recognising that "zero" was physically meaningful rather than a bug required fluid-dynamics knowledge the code could not supply.
The reproducible artifact. An attempted flow-direction comparison against the CFD returned a near-perfect anti-alignment — stable, reproducible, and entirely spurious, because it was the direction of a near-zero noise vector. Reproducibility is not validity. The correct move was to discard the metric entirely and replace it with one robust to the physics, which then confirmed the wake location honestly.
The Reproducibility Trap
An LLM will happily compute, plot, and caption a statistic without asking whether it means anything. A stable wrong number is more dangerous than a noisy one, because it survives sanity checks. Judging whether a metric suits the data is a human responsibility.
Complex Systems Need a Human Architect
Beyond individual numbers, the validation chained a video pipeline, multiple optical-flow algorithms, CFD output, and clashing coordinate systems. Each component worked; the integration kept failing. Correct image-processing code with no memory footprint awareness — the run was killed by the OS. Needed to be told that a top-down smoke image integrates over all heights, so comparing it to a single CFD slice is a modelling decision, not coding. When the comparison came back inconclusive, reporting the null honestly rather than tuning a threshold into false agreement was scientific integrity the model doesn't enforce. Architecture — scale, plane, memory, comparability — demands someone holding the whole system in mind.
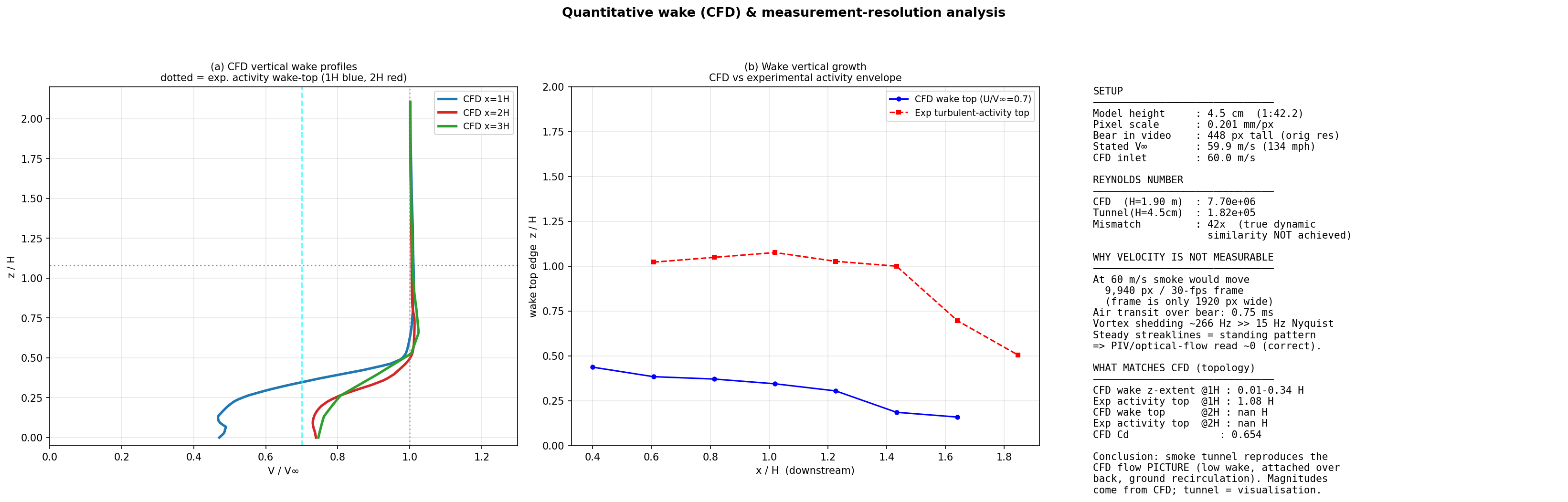
The CFD Can Be Wrong Too
So far this reads as catching the LLM's mistakes by checking against the CFD. But that framing hides the deepest trap: the CFD is not ground truth either. Its turbulence model is known to over-predict separation in some bluff-body configurations; steady RANS cannot capture transient shedding; and the predicted drag is the product of choices in closure, wall treatment, mesh, and domain — change any of them and the number moves. The simulation is a carefully reasoned hypothesis about the flow, not a measurement of it.
"When a crude experiment 'agrees' with a simulation on topology, it is tempting to call the simulation validated. But two methods can share the same wrong answer. Agreement is not correctness."
The smoke tunnel could confirm where the wake sits, but not measure a single velocity magnitude — so it never actually tested the CFD's quantitative claims. Breaking that circle requires a measurement that is genuinely independent and genuinely quantitative: matched flow conditions, calibrated instrumentation with quantified uncertainty, temporal resolution adequate to the physics, and controlled, repeated runs. Every one of those is a judgment-dense, hands-on task that cannot be delegated to a model which cannot feel a misaligned probe or notice a blocked pressure tap.
Neither the Code nor the Simulation Is Ground Truth
The LLM's analysis can be wrong. The CFD it is checked against can also be wrong — they can even be wrong together. The only adjudicator is a careful, human-designed, precisely-instrumented physical measurement. That experiment is not a formality at the end; it is the foundation.
How to Keep the Human in the Loop
The point is not to do less with LLMs — it is to place human attention where the failure surface is largest. Across this validation, a consistent division of labour emerged.
| Phase | LLM is strong at | Human must own |
|---|---|---|
| Setup | Boilerplate, API calls, file wrangling | Experimental design: what is measurable at all |
| Calibration | Proposing detection code | Imposing a known physical reference |
| Execution | Running tools, parsing output | Resource budgeting; sanity-checking intermediates |
| Analysis | Implementing metrics fast | Judging whether a metric is meaningful |
| Interpretation | Drafting clear narrative | Reconciling with physics; reporting honest nulls |
- 1
Anchor every number to an expectation before accepting it.
- 2
Verify calibration against a physical reference — never let an image-derived dimension stand unchecked.
- 3
Establish what is measurable before measuring — bound the experiment up front, not as a surprise.
- 4
Interrogate the metric, not just the value — stability is not meaning.
- 5
Let nulls be nulls — protect inconclusive results from being tuned into false agreement.
A Powerful Tool, Not an Autonomous Scientist
The companion study stands, and its final results are sound — but they are sound because a human caught the misread coefficient, recognised the zero-velocity artifact as physics, fixed the vision calibration, discarded the meaningless correlation, budgeted the memory, and reported the inconclusive comparison honestly. Remove that human and you do not get a slightly worse paper — you get a confident, well-formatted, wrong one.
The model collapses the cost of implementation to nearly nothing, which is transformative. It does not collapse the cost of judgment — and experimental work is judgment-dense in a way pure simulation is not, because it lives where abstractions meet a physical world that does not validate your inputs. The skill that matters most is no longer writing the analysis code; it is knowing, at every step, roughly what the answer should be, and refusing to accept the one in front of you until it earns your trust.
"Use the model for everything it is good at — which is a great deal. Just never confuse the fluency of its output with the correctness of its result. In the lab, those are different things, and only you can tell them apart."
Companion study: How LLMs Like Claude Opus Can Run a Complete CFD Study — the simulation whose validation is dissected here.